
AI 视频 Best Practice 周报 | 第 3 期(2026.04.07-04.10)
本期精选 6 条实践:HeyGen Avatar V 正式发布、Kling 3.0 五层级提示词框架、Runway Gen-4.5 图转视频工作流、多工具角色一致性系统化方案,以及复古胶片三层提示词与首尾帧无缝转场的风格化创作方法。

4 月 8 日,HeyGen 发布 Avatar V,把「手机录 15 秒」和「工作室级长视频稳定输出」这两件原本不挨边的事拼在了一起1。同期,Kling 3.0 的五层级提示词框架和 Runway 官方角色一致性指南也完成整理,生成可控性有了系统化的操作入口。本期 6 条实践,两条主线:工作流精度与风格化创意。
主线一:工作流与提示词技巧
BP-01 | HeyGen Avatar V:15 秒录制 → 工作室级数字人
工具:HeyGen Avatar V 发布日期:2026-04-08
大多数数字人模型在生成超过 20 秒后面部特征就开始漂移,Avatar V 的做法是在模型层面直接解决这个问题,而不是靠后期修补,HeyGen 声称可以全程保持稳定1。
三步工作流:
- 录制参考素材:15 秒自然对话视频,手机即可,无需专业设备;关键是光线均匀(避免逆光)、表情自然、服装简洁
- 构建身份模型:Avatar V 分析面部特征、动作习惯、微表情,构建完整身份模型
- 按需生成输出:指定不同穿搭、场景、背景,保持数字人外观一致;可搭配 Seedance 2.0 同步生成电影级动态镜头
四大核心能力1:
| 能力 | 说明 |
|---|---|
| 多角度一致性 | 不同机位、角度下身份稳定,无「恐怖谷」感 |
| 多外观生成 | 同一段录制素材生成不同服装/场景版本 |
| 长视频稳定 | 从第一帧到最后一帧无特征漂移 |
| 真实微表情保留 | AI 捕捉录制中的自然姿态与独特身体语言 |
实际价值在于可复制性:员工培训模块、多语言产品演示、入职视频——这类内容量大且需要频繁更新,Avatar V 配合 HeyGen 的 175 种语言自动配音,理论上一次录制可派生出数十个语言版本1。
BP-02 | Kling 3.0 五层级电影提示词框架
工具:Kling 3.0 来源:Atlabs.ai
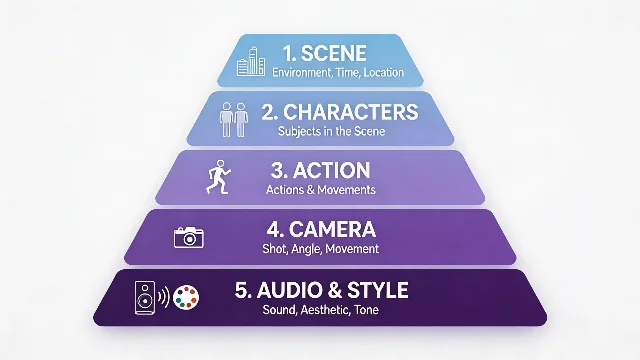
堆关键词和按结构写,生成质量差距在多镜头项目里会被放大几倍。这套框架要求按固定顺序写五层,每层职责不重叠2:
Layer 1 - Scene(场景锚点):位置、时间/光影、整体氛围
Layer 2 - Characters(角色):具体描述,固定标签,避免模糊指代
Layer 3 - Action(动作时间线):拆分步骤 + 时间标记
Layer 4 - Camera(摄影机):镜头类型、运镜方式、转场
Layer 5 - Audio & Style(音频与风格):对话、环境音、SFX、色彩基调Layer 3 的时间标记法是最容易被跳过的一步,但跳过它的代价是模型随机决定动作节奏:
First 0-2s: Sarah walks slowly from the left side
Middle 2-5s: She pauses to look at the portrait
Final 5-7s: She turns back and exits right多人场景示例(酒店大堂):
[Scene] Elegant hotel lobby at dusk with warm golden light and marble floors
[Character A] Marcus, 40s, dark suit, confident, standing by the window
[Character B] Elena, 35, red dress, anxious, approaching from the left
[Action] Marcus turns at 1s as Elena enters. Eye contact at 2s.
Handshake at 3s (Marcus extends), Elena hesitates then accepts at 4s.
[Camera] Medium shot of Marcus → push-in to their exchange → pull back to two-shot
[Audio] Soft piano, footsteps echo.
Character A (warmly): "I wasn't sure you'd come."
Character B (quietly): "I almost didn't."
[Style] Cinematic, warm color grading, shallow depth of field负向提示词标准配方2:
blur, flicker, distorted faces, warped limbs, unrealistic proportions,
deformed hands, extra fingers, mutation, glitch, warped text多镜头项目里,结构化框架把迭代轮数从 8-10 轮压缩到 3-5 轮是可以预期的结果;多人同框时,时间标记法的价值更直接:不写清楚「谁在第几秒先动」,模型会自行发挥,结果很难复现。
BP-03 | Runway Gen-4.5 图转视频七步工作流
工具:Runway Gen-4.5 来源:Curious Refuge
七步操作,有几个坑值得提前说3:
- 访问 Runway 官网 → 选择「Generate Video」
- 上传静态参考图
- 填写以动作为核心的提示词(去掉背景冗余描述)
- 确认选中 Gen-4.5 模型(界面默认未必是最新版)
- 选择画幅比例(电影首选 16:9)
- 设置时长(最长支持 10 秒)
- 生成,用内置 4K Upscale 处理终稿
关键提示词写法对比:
❌ 冗余描述型(模型不知道重点是什么)
A woman in a red jacket standing in a forest with tall trees
and sunlight filtering through the leaves on a quiet afternoon.
✅ 动作核心型(清晰告诉模型发生什么)
A woman running toward a burning barn,
then grabbing her head in panic.默认输出分辨率是 720p,专业项目需在 Runway 内置 4K Upscale 工具里单独处理。Gen-4.5 在人物运动和物体交互的物理感上是目前主流模型里表现偏强的一档,Curious Refuge 在测试中认为其物理运动逼真度超出同期主流模型3。
BP-04 | Runway 角色一致性系统化方案:从参考图到多角色管理
工具:Runway(角色参考功能) 来源:Runway 官方指南

Runway 官方把「上传一张照片就能保持角色一致」当成误区来纠正——实际上这套流程有四步4。
第一步:建立高质量参考图
合格参考图的硬性要求5:
✅ 分辨率最短边 ≥ 1024px
✅ 面部对焦清晰,无遮挡
✅ 光线均匀,无硬阴影
✅ 单一角色,简洁背景
✅ 正面或 3/4 角度
❌ 模糊/低分辨率
❌ 极端仰拍俯拍角度
❌ 重度滤镜、墨镜遮面
❌ 多人入镜Runway 官方的推荐方案:不要直接用手机随手拍的照片,而是先用文生图工具生成一张专门的参考肖像(中性光线、干净背景),再用于后续所有生成。这样质量可控、角度可选,也省去了照片质量差导致后续反复出问题的麻烦5。
第二步:多参考图组合
单张参考图遇到极端角度时容易出现一致性漂移。解决方案:上传 2-3 张同一角色不同角度的参考4:
- 主参考:正面肖像
- 辅参考 1:3/4 视角
- 辅参考 2:侧面或全身(需要全身场景时必备)
第三步:提示词只描述「要改的部分」
参考图已经锁定外观,提示词只需要说场景、动作、光线、摄像机角度;提示词中描述与参考图矛盾的特征(如「金发」但参考图是黑发)会直接破坏一致性5。
第四步:多角色场景的隔离策略4:
Step 1:单独测试角色 A 的一致性 → 保存最优参考
Step 2:单独测试角色 B 的一致性 → 保存最优参考
Step 3:AB 同框,先尝试简单站位(并排站立)
Step 4:逐步增加复杂交互(对视 → 握手 → 拥抱)给不同角色设计明显的视觉区分(发色、体型、年龄段、服装风格),可以大幅降低 AI 混淆特征的概率。
进阶技巧:用成功生成结果的最后一帧作为下一个场景的起始参考——在已有一致性的基础上继续生成,不用每次回到原始参考图重新开始5。
主线二:风格化与创意方法
BP-05 | 复古胶片风格化:三层提示词 + 后期调色参数表
工具:Kling 3.0 / 即梦 AI + 剪映

AI 生成视频默认会出现过饱和、过锐利的「塑料感」。胶片风格化和之前讲过的「去 AI 痕迹」不是同一件事——不是在消除 AI 感,而是主动给画面建立一套有历史纹理的视觉语言。以下三层提示词策略整理自国内创作者社区实践(微信/小红书),无独立原文 URL,见交付报告说明:
第 1 层:胶片品牌描述(必填)
Film stock: Kodak Portra 400 / Fujifilm Superia / Agfa Vista
Color palette: warm oranges and teal shadows / faded yellows / muted greens
Texture: visible grain, slight color shift, gentle vignette
Light quality: soft golden hour, diffused sunlight, natural lens flare第 2 层:反向修正(建议加)
NOT: digital clean, oversaturated, plastic look, HD clarity,
modern crisp details, neon colors, harsh shadows第 3 层:参考风格(可选)
Inspired by: Wong Kar-wai cinematography,
Spike Jonze films, 1980s indie movies
Mood: nostalgic, melancholic, intimate, vintage wanderlust剪映后期调色参数表(复古胶片基础版):
| 参数 | 复古胶片 | 80s VHS | 电影黑白 |
|---|---|---|---|
| 对比度 | -10 | -15 | +5 |
| 饱和度 | -20 | -30 | 0% |
| 色温 | +300K(偏暖黄) | +500K(橙红) | 中性 |
| 青色阴影偏移 | 开 | 品红/青混合 | 冷调 |
| 胶片噪点 | 0.12 | 0.25 | 0.08 |
| 晕影强度 | 30% | 40% | 20% |
两步叠加的逻辑:生成阶段用胶片描述词在源头压制过饱和,后期调色再统一色彩基调。单用其中一步通常不够自然,两步配合后画面的「做旧感」才会有说服力。
BP-06 | 首尾帧无缝转场:用末帧驱动下一个镜头
工具:Kling 3.0(图转视频模式)
首尾帧控制最常见的用法是保留起始图的文字和标识。但它更实用的一个场景是做镜头链:第一段视频的末帧,直接作为第二段的起始帧,角色位置、光影状态、空间关系全部继承2。
三类典型应用2:
| 场景 | 提示词重点 | 推荐 Motion Intensity |
|---|---|---|
| 无缝循环(呼吸、水流) | 「微妙运动,起末帧相同」 | 0.3-0.4(低幅) |
| 场景切换转场 | 「与上一帧保持光影一致,人物从同方向进入」 | 0.4-0.5 |
| 产品/UI 展示(保留文字标识) | 「仅引入背景动态变化,保留前景所有文字和标识」 | 0.3 |
一镜到底连续流的操作路径:
生成镜头 A → 导出最后一帧 →
以该帧为起始图生成镜头 B,提示词描述动作延续方向 →
导出镜头 B 最后一帧 → 以此类推Motion Intensity 0.4 是个可靠的起点。用末帧传递信息比在提示词里描述「接着上一个镜头的末尾状态……」要稳定得多——文字描述这类时序关系,模型理解偏差很大。品牌视频里需要「一气呵成」的连贯感,或者叙事短片里想避免硬切割裂感,这个方法值得先跑几组测试。
下周值得盯的方向:Avatar V 刚发布几天,目前社区反馈还是以「首测印象」为主,企业实际项目的批量生产反馈还没跟上来;Kling 3.0 Omni 多模态输入也有创作者在测试参数组合,目前还没见到足够可复现的系统性总结——如果有好的案例出现,第 4 期会跟进。
Add more perspectives or context around this Post.